Looker Studio: Eine Reise in die Welt der Data Stories …
Looker Studio ist die naheliegende Wahl für all diejenigen, die Daten aus dem Google-Ökosystem visualisieren möchten, da es vollständig in den Google Workspace integriert ist. Darüber hinaus schreibt es sich eine besonders einfache Handhabung auf die Fahne und bietet die Anbindung an zahlreiche andere Datenquellen oder auch die direkte Einbettung von Visualisierungen auf Webseiten an. Unter den BI-Tools platziert sich Looker Studio damit schnell als leichtgewichtiger Generalist.
Obwohl – oder gerade weil – Looker Studio sein Versprechen der Einfachheit einhält, fehlen einige Funktionalitäten und Visualisierungen, die in anderen Tools standardmäßig integriert sind. Weitere Features, wie beispielsweise Parameter, sind zwar vielseitig einsetzbar, jedoch nur spärlich dokumentiert und erfordern einiges an Experimentierarbeit, um ihr Potential vollständig zu durchdringen.
Um euch dabei zu helfen, eure Data Stories effizient und anschaulich mit Looker Studio zu vermitteln, haben wir eine Auswahl von Best Practices und Workarounds für den e-dynamics Blog zusammengestellt. Anhand der in BigQuery öffentlich zugänglichen Chicagoer Kriminalitätsstatistik zeigen wir euch, wie ihr Graphen mit Parametern dynamisch steuert, simple Vorhersagen erstellt und Data Blends nutzt, um einige der Limitierungen von Looker Studio zu überwinden.
Dynamische Steuerung von Views mit Parametern
Looker Studio bietet nicht nur die Möglichkeit, Dimensionen und Metriken zu nutzen, sondern auch Parameter. Diese können entweder numerische oder kategorische Daten enthalten und vom Betrachter eines Dashboards direkt manipuliert werden. In unserem Beispiel verwenden wir einen Parameter, um dem Nutzer die Entscheidung zu überlassen, welche Metrik in einem Graphen dargestellt werden soll.
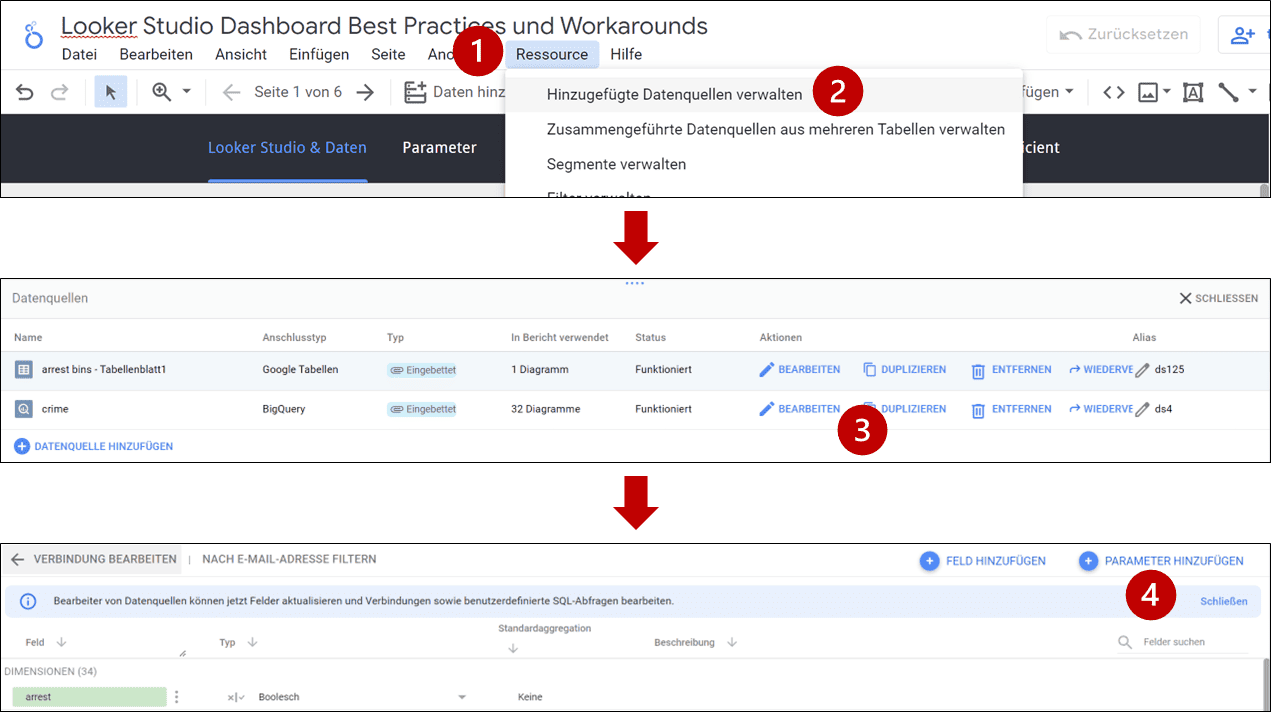
Zunächst erstellt ihr einen Parameter unter (vgl. Abb 1):
- Ressource -> Hinzugefügte Datenquellen verwalten -> bearbeiten (der gewünschten Datenquelle) -> Parameter hinzufügen
Looker Studio Abbildung 1
Looker Studio Abbildung 1
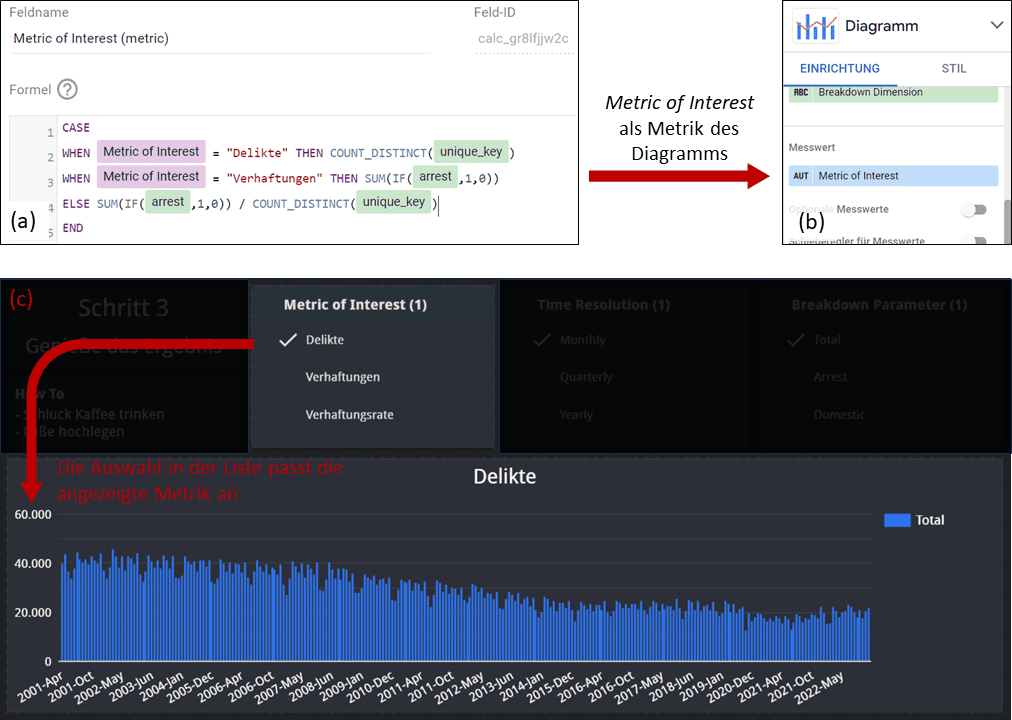
Hier vergebt ihr einen Namen, wählt einen Datentyp und gebt die gewünschten Ausprägungen an. In unserem Fall Delikte, Verhaftungen sowie Verhaftungsrate (Verhaftungen pro Delikt). Der Parameter kann nun für unterschiedliche Steuerelement genutzt werden, z.B. für eine Single-Choice Liste wie in Abb. 2c gezeigt.
Als nächstes erstellen wir eine Metrik, die ihren Wert je nach der aktuellen Auswahl des Parameters anpasst. Dies kann über eine einfache Case-Struktur realisiert werden. Diese Metrik wird schließlich in einem Graphen dargestellt (s. Abb. 2a und b). Verändert der Nutzer nun den Wert des Parameters, werden die dargestellten Daten im Graphen automatisch angepasst. In unserem Dashboard haben wir diesen Ansatz außerdem genutzt, um die Auflösung der Zeitachse zu beeinflussen, eine beliebige Breakdown Dimension zu wählen sowie den Titel des Graphen dynamisch anzupassen.
Looker Studio Abbildung 2
Looker Studio Abbildung 2
Vorhersagen
Zugegeben: so präzise Vorhersagen wie sie unser Data Analytics Team erreicht (s. auch Anomalie-Detektionstool ed.Detect), lassen sich mit Looker Studio nicht erzeugen. Für eine einfache Abschätzung der Form „Wo landen wir, wenn sich die Zahlen im Rest des Jahres so entwickeln wie im vergangenen Jahr?“ reichen die Mittel allerdings aus, wenn auch der Weg kein offensichtlicher ist. Der Kern des Problems dabei ist, dass Looker Studio das Verrechnen von Daten aus unterschiedlichen Zeilen einer Datenquelle nicht ohne Weiteres unterstützt.
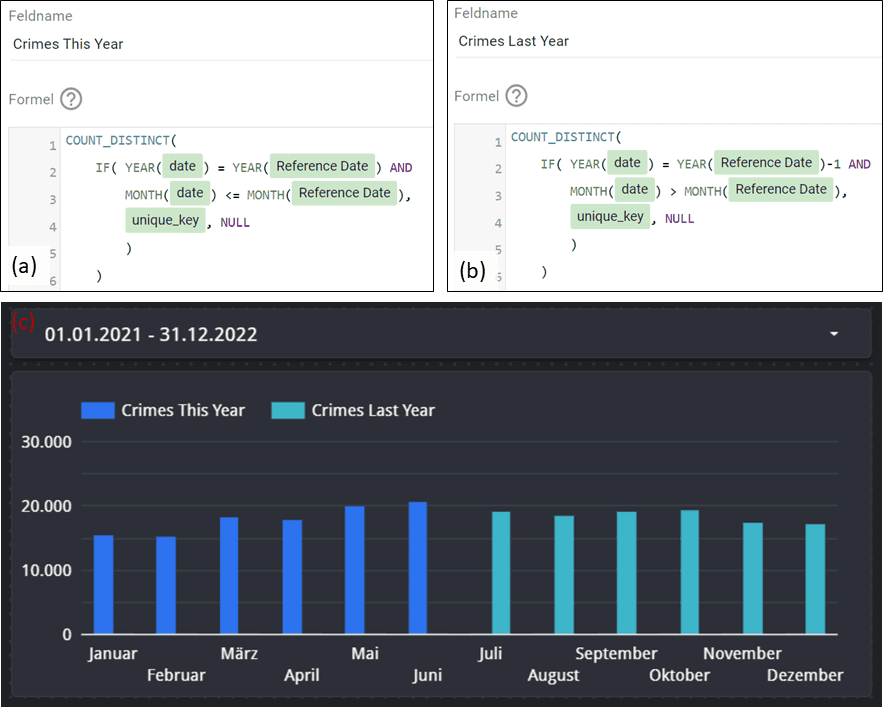
In unserem Workaround nehmen wir an, wir befänden uns im Juli 2022 und wollen die Gesamtzahl der Delikte bis zum Jahresende auf Grundlage des Vorjahres prognostizieren. In unserem Dashboard setzen wir diesen Referenztag im Juli durch eine entsprechende Dimension, könnten aber zum Beispiel auch die TODAY()-Funktion nutzen, damit sich die Visualisierung dynamisch für den aktuellen Tag anpasst. Als nächstes erstellen wir zwei Metriken:
- Crimes This Year: Die Delikte dieses Jahres von Januar bis Juni sind uns bekannt. Wir schneiden daher alle Daten 2022 nach Juni ab und zählen die Delikte anhand ihrer eindeutigen ID (s. Abb. 3a). Dieser Schritt wurde ob der Beispieldaten künstlich eingeführt. In einem realen Anwendungsfall müsste man an dieser Stelle keine Datenpunkte entfernen, da sie einfach nicht vorhanden sind. Schließlich sollen sie ja vorhergesagt werden.
- Crimes Last Year: Aus 2021 wollen wir alle Delikte von Juli bis Dezember benutzen. Entsprechend werden die Delikte der Monate Januar bis Juni entfernt und abermals gezählt, was übrig bleibt (s. Abb. 3b).
Looker Studio Abbildung 3
Looker Studio Abbildung 3
Werden beide Metriken in einem Balkendiagram monatsweise aufgetragen, ergibt sich der Graph in Abbildung 3c. Wichtig dabei ist, dass wir die Daten auf 2021 und 2022 filtern, bei der Darstellung aber die Jahreszahl entfernen. Dadurch summiert Looker Studio die Daten für jeden Monat über alle Jahre auf. Durch unsere Cut-offs in den Metriken sowie den Zeitraumsfilter erreichen wir auf diese Art, dass die Monate Januar bis Juni nur Daten aus 2022 und Juli bis Dezember die Daten aus 2021 enthalten.
Von hier an ist der Rest einfach: Wir summieren beide Metriken auf, kumulieren die Daten über die Monate (Eigenschaften der Metrik innerhalb des Graphen -> Laufende Berechnung -> Laufende Summe) und erhalten damit den Graphen in Abbildung 4. Wir sehen, dass die Zahl der Delikte von Januar bis Dezember kontinuierlich wächst. Wir können dem Graphen entnehmen: Würde ab Juli 2022 die gleiche Zahl von Delikten wie in 2021 verübt, würde Chicago Ende des Jahres die traurige Gesamtzahl von über 219 000 Vergehen zu berichten haben.
Zwei Extras könnt ihr darüber hinaus im Graphen erkennen: 1) mit Hilfe einer Breakdown Dimension in Abhängigkeit des Datums, konnten wir die vorhergesagten Balken farblich abgrenzen. 2) Wir haben eine Referenzlinie benutzt, um den vorhergesagten Wert hervorzuheben.
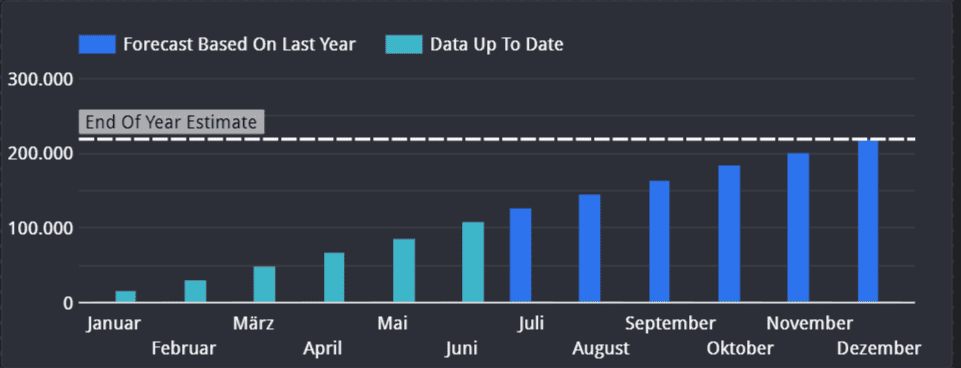
Looker Studio Abbildung 4
Looker Studio Abbildung 4
Saisonale Schwankungen
In einem Anwendungsfall wurden wir von unserem Kunden gebeten, eine Metrik relativ zu ihrem Wert im Januar des aktuellen Geschäftsjahres darzustellen, um so einen schnellen Blick auf die Stärke von saisonalen Schwankungen zu ermöglichen. Doch wie sich herausstellte, war das in Looker Studio nicht so einfach umzusetzen wie es zunächst klingt. Das Problem ist abermals, dass wir die Daten für jeden Monat einzeln zwar kumulieren können, es aber nicht möglich ist, den Januar direkt mit den anderen Monaten vergleichen. Unsere Lösung führt uns über das Zusammenführen von Datenquellen, auch bekannt als Data Blends (oder „Join“ für die Leser, die aus dem SQL Lager kommen). Wie Data Blends grundsätzlich funktionieren und in Looker Studio konfiguriert werden, könnt ihr hier in Erfahrung bringen.
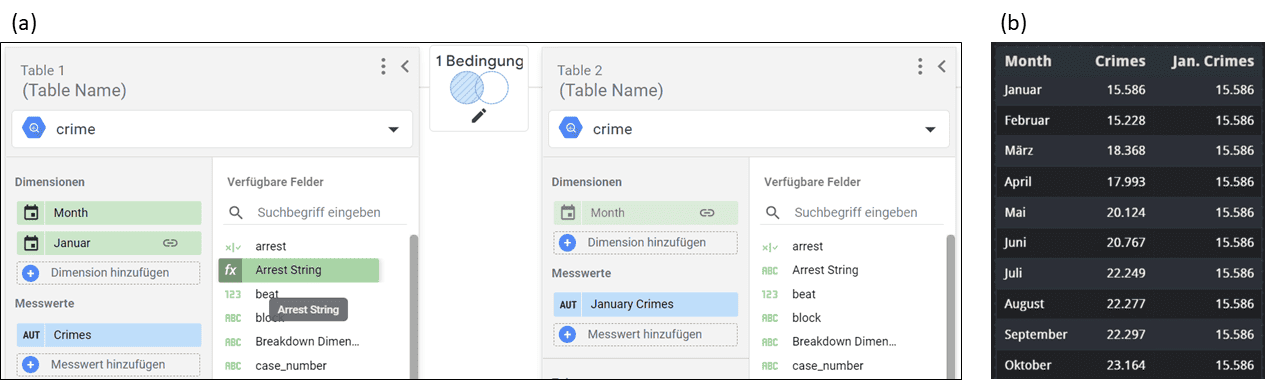
Looker Studio Abbildung 5
Looker Studio Abbildung 5
In unserem Fall führen wir die Datenquelle genau gesagt mit sich selbst zusammen. Wie in Abbildung 5a zu sehen ist, haben beide Tabellen des Blends den Monat als Dimension und die Anzahl von Verbrechen als Metrik, was den ersten beiden Spalten in Abbildung 5b entspricht. Tabelle 1 enthält eine zusätzliche Spalte, in die wir als Konstante „Januar“ eintragen – unabhängig vom tatsächlichen Monat. Konfigurieren wir unseren Blend nun als left-join zwischen der Januar-Spalte von Tabelle 1 und der Monatsspalte von Tabelle 2, so wird die Anzahl der Delikte im Januar aus Tabelle 2 extrahiert und in jede Zeile der Ergebnistabelle geschrieben, was in der letzten Spalte in Abb. 5b gesehen werden kann.
Schließlich zeigt Abbildung 6 das erhoffte Ergebnis. Da die Anzahl der Delikte im Januar in jeder Zeile unseres Blends auftaucht, können wir zwischen Januar und einem beliebigen anderen Monat die gewünschte Rechenoperation ausführen: In unserem Fall die Differenz beider Monate, normiert auf Januar. Dank Data Blends können wir jetzt saisonale Schwankungen schnell und einfach erkennen.
An dieser Stelle ein kurzes Wort der Warnung: Obwohl Data Blends ein vielseitig einsetzbares Werkzeug sind, haben sie auch ihre Tücken. Mit wachsender Datenmenge werden sie schnell enorm langsam und sind sogar auf eine Maximalzahl an Zeilen limitiert. Außerdem ist eine Validierung der Blends enorm wichtig, da die Ergebnisse gerne mal von den Erwartungen abweichen.
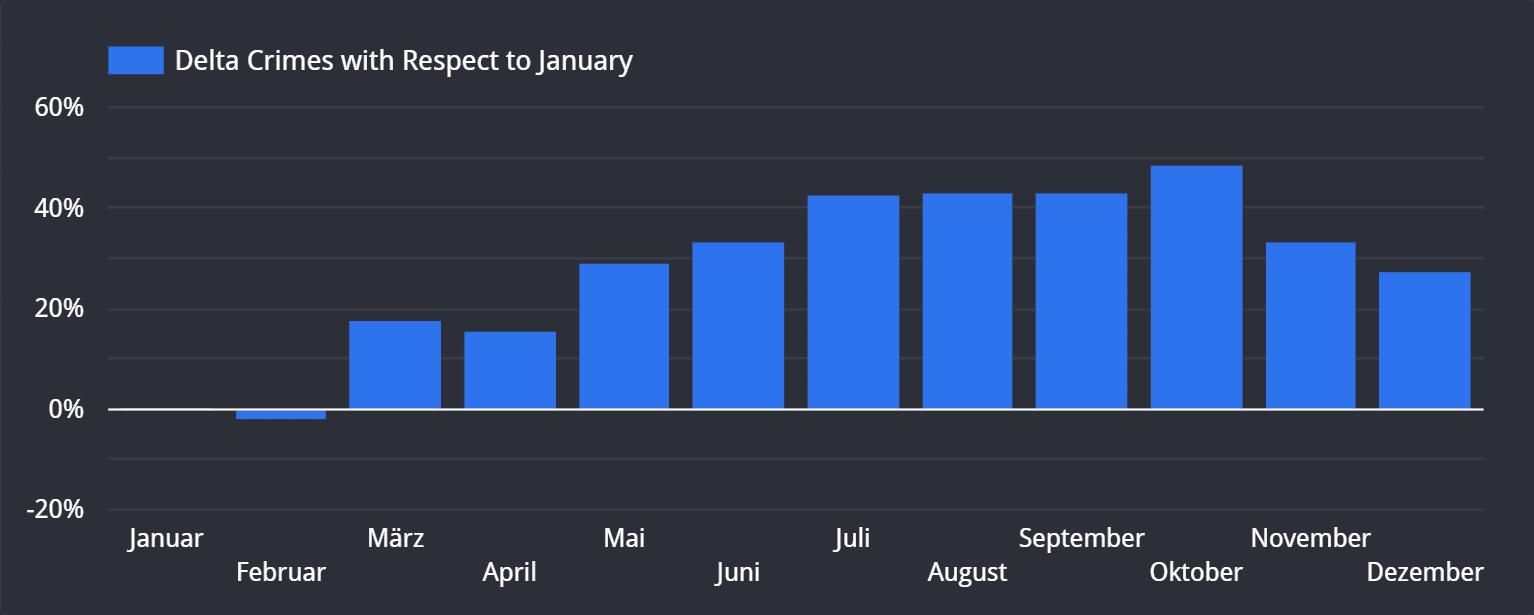
Looker Studio Abbildung 6
Looker Studio Abbildung 6
Histogramme
Eine wenig nachvollziehbare Schwachstelle von Looker Studio ist das Fehlen von Histogrammen, welche die wohl grundlegendste Visualisierung von Häufigkeitsverteilungen darstellen. Aber auch hier können uns Data Blends helfen, einen Workaround zu realisieren. Unser Ziel ist es die Anzahl der Verhaftungen jedes Chicagoer Bezirks in Bins einzuordnen. Die Bins sind gemäß der Metrik arrests binned in Abb. 7 definiert, d.h. gab es zwischen 0 und 2000 Verhaftungen fällt der Bezirk in Bin „2000“, zwischen 2000 und 5000 Verhaftungen wird es Bin „5000“ und so weiter.

Looker Studio Abbildung 7
Looker Studio Abbildung 7
Das Problem an dieser Stelle ist, dass Metriken nicht als Dimension für Balkendiagramme verwendet werden dürfen. Ein naheliegender Ansatz wäre wieder ein Selfblend. Führen wir diesen mit ward als Dimension und arrests binned durch, werden beide Größen in der Ergebnistabelle als Dimensionen geführt. Leider macht uns Looker Studio bei diesem Ansatz einen Strich durch die Rechnung: erstellen wir ein Balkendiagramm aus dieser Tabelle, erhalten wir nicht die gewünschte Häufigkeitsverteilung. Stattdessen werden alle Bezirke in einem einzelnen Bin zusammengefasst, während auf der Abszisse die Gesamtzahl der Verhaftungen aufsummiert wird. Die Logik dahinter entzieht sich uns bis heute.
Aus diesem Grund schmücken wir unseren Workaround mit einem weiteren Workaround aus: wir ergänzen unseren Bericht zunächst um eine zusätzliche Datenquelle, welche die Bins erneut definiert. In unserem Beispiel ist dies in Google Sheets umgesetzt (Abb. 8a). Der in Abbildung 8b dargestellte Blend basiert auf einem inner join zwischen unserer Metrik arrests binned mit der arrests Dimension der Google Sheets Quelle und führt zu der Ergebnistabelle Abb. 8c. Diese Tabelle wird schließlich für das Balkendiagramm in Abb. 8d genutzt. Als Dimension wird dazu arrests binned gewählt, während wir als Metrik die wards zählen (Anm.: hierfür muss in der Zusammenfassung der Metrik „Anzahl“ ausgewählt werden). Das Resultat ist ein Histogramm mit unseren vordefinierten Bins auf der x-Achse sowie der Anzahl der Bezirke pro Bin auf der y-Achse.
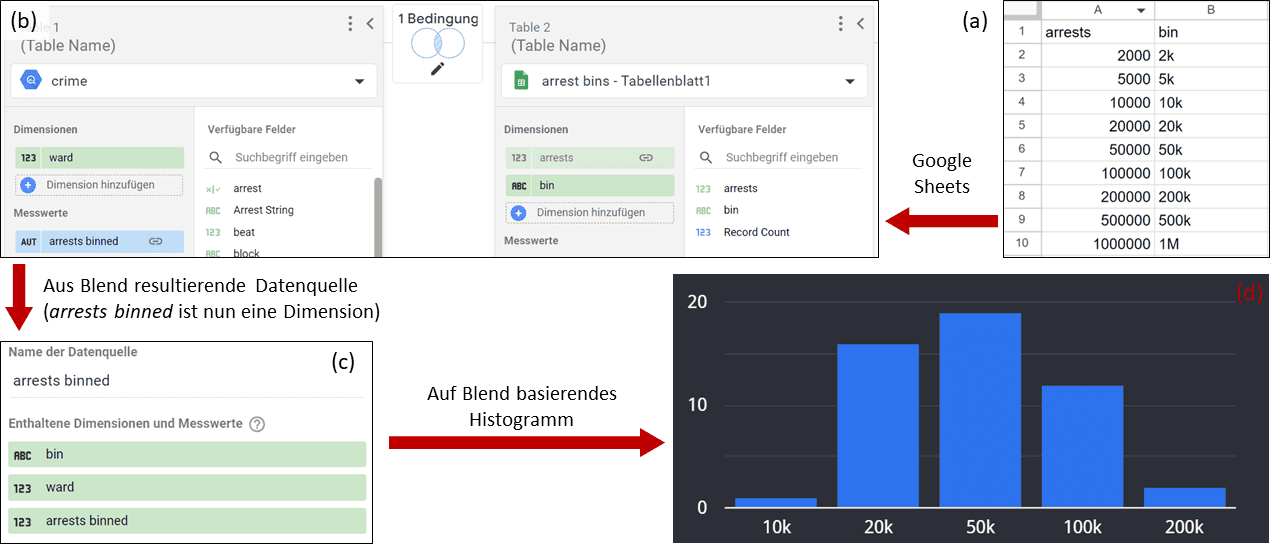
Looker Studio Abbildung 8
Abbildung 8
Gerne beraten wir bei den Möglichkeiten zum Einsatz von Looker Studio sowie bei der Migration zu GA4 in eurem Unternehmen. Sprecht uns an!
Feedback
Wir freuen uns über Feedback und weiteren Austausch zu Looker Studio, Vorhersagen und Best Practices.