Datenvisualisierung beschreibt die grafische Darstellung von Daten und Informationen. Die Visualisierung hilft dabei zugrundeliegende Daten für Außenstehende schnell verständlich aufzuzeigen. Es ist eine gängige Methode um Trends, Ausreißer oder Muster in Daten festzustellen. Gerade in der Welt von Big Data ist die Datenvisualisierung wichtig, um daraus Handlungsempfehlungen abzuleiten.
Welche Richtlinien sollten bei der Datenvisualisierung beachtet werden?
Zunächst ist es wichtig, sich Hintergrundwissen zu den Daten anzueignen. Vorhandenen Daten können nur ansprechend visualisieren werden, wenn sie auch verstanden werden. Ein weiterer wichtiger Punkt ist die Frage nach dem Ursprung der Daten. Woher kommen die vorliegenden Daten? Sie können von einer Umfrage oder einer Datenbank kommen, aber auch automatisch oder manuell eingepflegt sein.
Der letzte wichtige Punkt ist die Frage nach dem Ziel. Was soll mit der Datenvisualisierung erreicht werden?
Wie werden Daten am besten aufbereitet?
Ausgehend davon, dass die Daten in geeigneter Form vorliegen, müssen diese in einem geeigneten Zustand sein. Oder gibt es Ausreißer, fehlende Angaben oder Verfälschungen? Ist das der Fall, muss der Umgang mit den Daten definiert werden. Die Daten müssen ggf. weiter gefiltert, zusätzlich kalkulierte Metriken oder Datentransformationen ergänzt werden.
Wenn alle nötigen Daten vorliegen, können diese visualisiert werden. Doch wer soll angesprochen werden? Die Zielgruppe muss von vorab klar definiert sein. Es gilt auch zu unterscheiden, in welchem Kontext die Visualisierung wahrgenommen wird. Bei einem Vortrag wird der Zuhörer an die Daten herangeführt und bekommt diese erklärt. In einer Mail soll für den Leser gleich eindeutig erkennbar sein, was die visualisierten Daten aussagen. In diesem Zusammenhang sind auch zwei Vorgehensweisen zu beachten: Exploratory und Explanatory.
Exploratory lässt den User interaktiv in den Daten nach Thesen suchen (Dashboards).
Explanatory beschreibt ein gefundenes Ergebnis, meist als PDF- oder XLS-Datei.
Tipps & Tricks bei der Datenvisualisierung
Grundsätzlich gibt es keine festen Regeln, die besagen, welches Diagramm wann das Beste ist. Allerdings gibt es einige Tipps, die wir hier gerne vorstellen:
- Je weniger Zeit der Betrachter braucht, um die Information zu erhalten, desto besser. Daher ist es wichtig, dass der Betrachter seine Fragen auf den ersten Blick beantworten kann.
- Die Visualisierung sollte recht einfach gehalten sein. Viele Tools fügen standardmäßig Informationen an, die nicht unbedingt notwendig sind (Gitternetzlinien, Datenbeschriftung, bunte Farbpalette).
- Den Betrachter nicht mit zu vielen Informationen verunsichern. Sondern eher mit Farbe, Positionierungen und Hervorhebungen arbeiten. Zudem bestimmte Dinge durch Ausrichtung in den Hintergrund rücken.
- Darstellungsmethoden mit 3D-Effekten und Animationen wirken oft unprofessionell und lenken vom Wesentlichen ab.
- Es gibt viel Literatur, die bei der Wahl für eine Visualisierung hilft. Auf dem Blog „Storytelling with data“ sind hilfreiche Tipps sowie Beispiele zu finden, wie Datenvisualisierung nicht umgesetzt werden sollte.
- Eine gute Visualisierung ist nicht nur inhaltlich richtig, sondern auch optisch ansprechend („Denke wie ein Designer“). Das Corporate Design des Unternehmens muss dabei beachtet werden.
- Diagramme können lügen. Ein gutes Beispiel: eine besonders kleine Skala in einer Zeitreihe, um die Schwankungen größer aussehen zu lassen. Hier sollte kein falsches Bild suggeriert werden.
- Bei größeren Projekte sollte eine Geschichte mit den Visualisierungen erzählen werden. Dies verdeutlicht die Fragestellung und macht einen Vortrag interessant.
Tools zur Datenvisualisierung
Natürlich gibt es verschiedene Tools, die bei der Datenvisualisierung unterstützen. Wir zeigen in den folgenden Abschnitten, welche Visualisierungstools es gibt und wo jeweils deren Stärken liegen.
Excel (Standard Tool)
Excel stellt ein weitverbreitetes Standardtool mit einer Vielzahl an Einstellungsmöglichkeiten dar. Fast alle Elemente können einzeln angesteuert und personalisiert werden. Allerdings ist Excel nicht für sehr große Datenmengen geeignet und Datentransformation sind nur bedingt möglich. Ebenso sind interaktive Dashboards meist nur mit sehr großem Aufwand möglich.
Business Intelligence Lösungen
Beispiele: Data Studio, Power BI, Qlik Sense, Tableau
Mit diesen Tools sind sehr große Datenmengen und Transformationen sowie interaktive Dashboards mit mehreren Seiten umsetzbar. Komplexere Fragestellungen können mit genügend Know-how des Tools umgesetzt werden. Für den Betrachter können die Daten bspw. als Präsentation aufgearbeitet oder als regelmäßige, saubere Datenquelle zur Verfügung gestellt werden.
R (Profitool)
Für dieses Tool sind riesige auch Datenmengen und anspruchsvolle statistische Analysen kein Problem. Mit frei verfügbaren Visualisierungspaketen (z.B. ggplot, plotly) sind in Sachen Visualisierung kaum Grenzen gesetzt. Allerdings sind dafür entsprechendes Fachwissen und Programmierkenntnisse nötig. Es eignet sich sowohl als interaktives Dashboard als auch für Exporte einzelner Ergebnisse.
Es gibt einige Möglichkeiten sein Wissen über Datenvisualisierung zu erweitern. Unteranderem, wie im Text bereits erwähnt, ist der Blog von Cole Nussbaumer „Storytelling with Data“ sowie der Blog von Nathan Yau „Flowingdata“ sehr hilfreich. Eine weitere Empfehlung ist das Buch „Grammar of Graphics“, welches als Basis für das R Paket ggplot dient.
Beispiele zur Visualisierung
Es folgen zwei Beispiele von Datenvisualisierungen, welche dieselbe Datengrundlage besitzen. Die Information wird jedoch auf verschiedenen Wegen übermittelt. Dazu sei gesagt, dass keine der beiden Visualisierungen falsch ist, denn die Daten werden bei beiden Versionen richtig abgebildet. Nur in der Art und Weise wie die Fragestellung beantwortet wird, unterscheiden sie sich im Wesentlichen.
In diesem Fall war die Fragestellung an die Datengrundlage folgende:
„Wie entwickelt sich die Channel Perfomance der vier Top-Channel im Laufe eines Monats?“
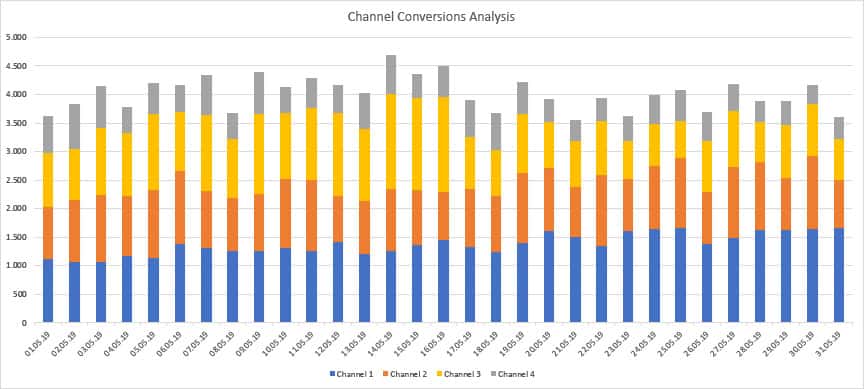
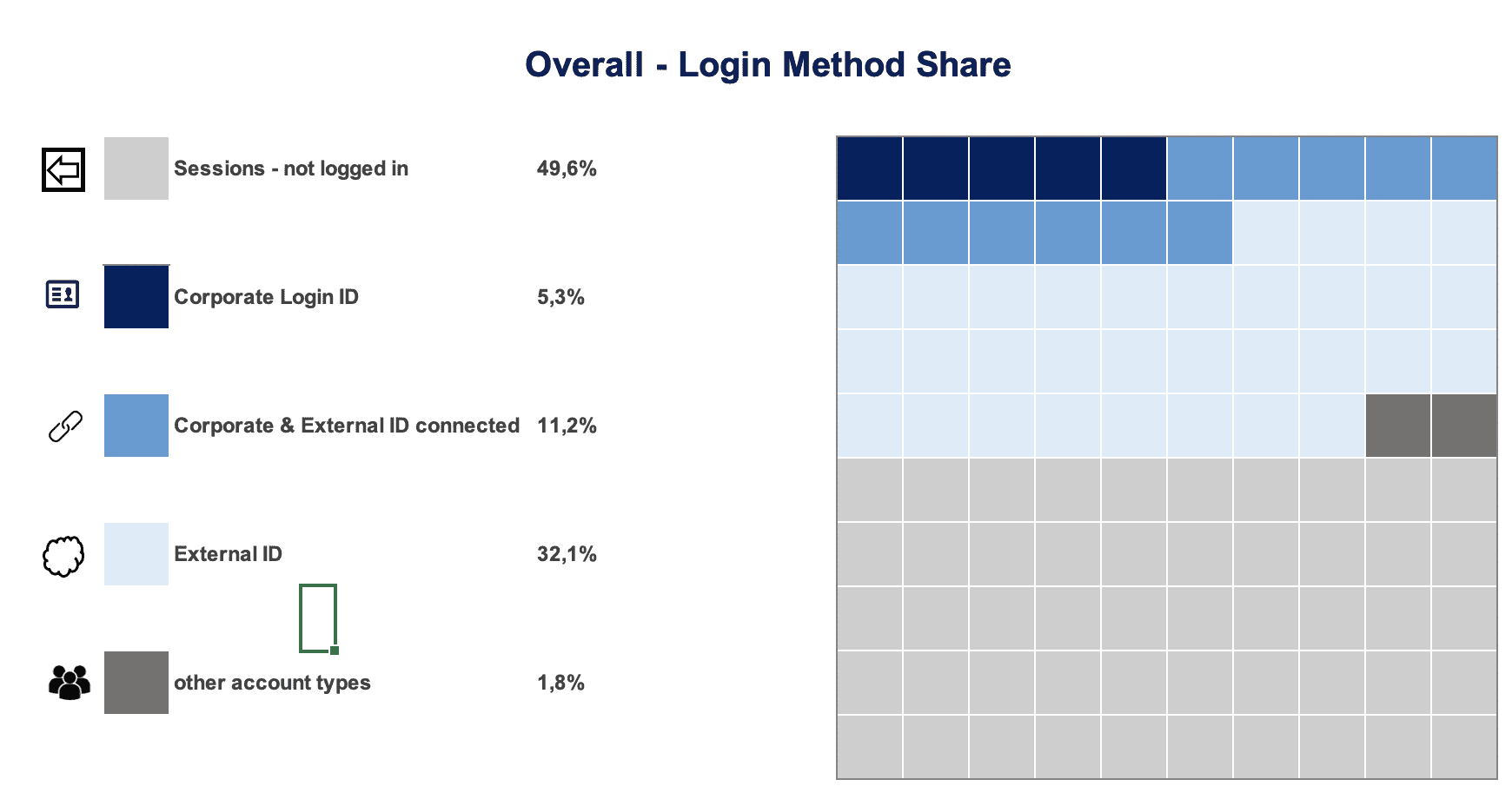
Abbildung 1
Die Visualisierung (Abbildung 1) wurde vom eingesetzten Visualisierungstools automatisch erzeugt. Es wird ein gestapeltes Säulendiagramm genutzt. Auf den ersten Blick ist der Gesamttraffic sichtbar. Innerhalb einer Säule ist die Verteilung auf die Channel dargestellt.
Was jedoch nicht direkt erkannt werden kann, sind die absoluten Trafficdaten pro Channel. Diese müssen bei Bedarf aus jeder Säule errechnet werden. Zu sehen ist in diesem Beispiel erstmal nur, dass der Gesamttraffic recht stabil im betrachteten Monat war. Die obige Fragestellung lässt sich also nicht ohne Weiteres beantworten. Des Weiteren könnte man noch die Farbgebung kritisieren, welche keinen Fokus auf bestimmte Informationen lenkt.
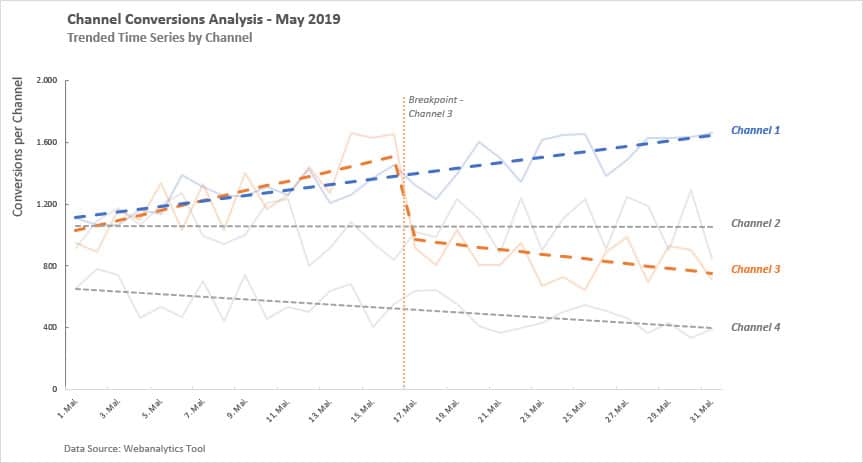
Abbildung 2
In diesem Beispiel (Abbildung 2) wird die Datengrundlage durch vier einzelne Zeitreihen inklusive Trendlinie dargestellt. Farblich hervorgehoben sind die beiden verhaltensauffälligen Channel 1 (starker Uplift) und 3 (spontaner Drop). Markiert ist außerdem der genaue Tag des Channel 2 Breakpoints.
Durch die Hervorhebung der Trendlinien ist die wesentliche Entwicklung der Channel direkt ersichtlich. Um den Fokus noch mehr auf die Trendlinien zu legen, wurden die Zeitreihen des tatsächlichen Verlaufs ausgegraut. Es wurde komplett auf zusätzliche Hilfslinien wie z.B. Gitternetzlinien verzichtet. Eine nicht zu fein gewählte Skala der Achsen und aussagekräftige Beschriftungen und Überschriften runden das Bild ab.
In diesem Beispiel wird ersichtlich, dass die Gestaltenden während der Entwicklung der Visualisierung nie die Fragestellung aus den Augen verloren haben. Mit einem Blick sind die wichtigen Informationen in einer Abbildung zusammengefasst worden. Dabei flossen neben gestalterischen Fähigkeiten auch fachliche Kompetenzen in das Ergebnis ein, welche die Bewertung der Channelverläufe in interessante und weniger interessante Verläufe ermöglichten.
Ist dieses Thema für Ihr Unternehmen interessant oder haben Sie weitere Fragen zur Datenvisualisierung? Dann melden Sie sich gerne direkt bei uns.



