Was ist eigentlich Data Mining?
Vielen denken dabei vielleicht an komplizierte Berechnungen, durchgeführt in großen Rechenzentren anhand einer riesigen Menge von Daten. Data Mining beginnt jedoch schon viel früher und die Einstiegshürde ist viel kleiner, als man vielleicht denken mag. Beim Data Mining geht es nicht primär darum Daten zu sammeln, sondern es geht vor allem darum, aus vorhandenen Daten Erkenntnisse zu ziehen. Das Mining bezieht sich also hierbei auf das Wissen, dass in den Daten liegt. Dabei müssen die Daten nicht notwendigerweise Big Data sein. Typischerweise werden Methoden aus den Bereichen Informatik und Mathematik angewandt, um das Wissen zu extrahieren. Die prominentesten Verfahren sind momentan dabei Machine Learning, Künstliche Intelligenz und Deep-Learning. Aber auch schon im Kleinen und ohne großartige Vorkenntnisse lässt sich Data Mining betreiben. Die Ergebnisse können dabei Muster, Trends oder Zusammenhänge in den Daten sein. Dabei ist es wichtig, die Erkenntnisse geeignet zu transportieren. Dies hängt stark von der Fragestellung, aber auch von dem Kenntnisstand der Fragenden ab.
Betrachten wir den Wikipedia Artikel zum Thema Data Mining und machen daraus eine „Wordcloud“, so können wir ohne großen Aufwand die wichtigsten Schlagworte herausfiltern. Abgesehen von Begriffen wie „Bearbeiten“, „Quelltext“ oder „Hauptartikel“, welche nur aufgrund der Eigenheiten einer Wikipedia-Seite in der Wordcloud gelandet sind, scheinen folgende Begriffe wichtig zu sein:
- Data = Datengrundlage
- Verfahren = (automatisierbare) Verfahren, statistische Methoden
- Clusteranalyse = Auffinden von zusammenhängenden Gruppen
- Ausreißer-Erkennung = Identifikation von unnormalem Verhalten
- Regressionsanalyse = Zusammenhänge in den Daten aufzeigen
- Klassifikation = Einteilung von Datenobjekten in Segmente.
Und ohne große Vorkenntnisse haben wir mit diesem kleinen Einstieg schon Data Mining betrieben. Unser Datensatz war dabei der Wikipedia Artikel, unser Verfahren das Bilden einer Wordcloud und unser Ergebnis, das Wissen über die wichtigsten Kategorien beim Data Mining.
Auf der Suche nach dem Schlüssel zum Nummer Eins Hit …
Wir möchten nun aber nicht jedes dieser Fachgebiete bis ins kleinste Detail ausleuchten und mathematisch korrekt auf deren Feinheiten eingeben. Wir wollen lieber die Idee der Verfahren genauer erläutern, sodass sich am Ende eine Vorstellung über Anwendungsgebiete, eventuelle Stolpersteine und allgemeine Tipps & Tricks zum Umgang gemacht werden kann. Und am besten lässt sich dies mit Hilfe von Beispielen machen.
Unser Datensatz basiert auf zwei Tabellen, welche wir von der frei zugänglichen Plattform kaggle.com heruntergeladen haben. Diese umfassen jeweils die populärsten und unpopulärsten (Chart) Songs vom Musikanbieter Spotify aus dem Jahr 2022.
Einen Überblick über die beinhalteten Spalten findet ihr nachfolgend. Neben dem Titel und den Künstler:innen der Songs, gibt es noch Infos zu den Chart Platzierungen und Popularität, Spotify-interne Kategorien des Songs wie z.B. „Tanzbarkeit“ oder Energie, sowie musikalisch Einordnungen und Beschreibungen des Songs.

Zu Beginn einer Analyse sollte man sich stets zuvor mit dem Datensatz vertraut machen, um eventuell fehlende Werte oder Besonderheiten zu identifizieren und entsprechend darauf reagieren. Dazu schauen wir uns zu Beginn die Künstler:innen mit den meisten Songs, jeweils für die populären und die unpopulären Songs an.

Die Künstler:innen der unpopulären Songs scheinen aus dem Genre Meditation und Entspannung zu kommen. Auch wenn diese Künstler:innen für einen selbst unbekannt sein mögen, darf man daraus nicht ableiten, dass ihre Musik „schlechter“ ist als andere. Denn beim Data Mining ist es wichtig, dass wir uns auf das Beobachten, Beschreiben und Analysieren beschränken und die Ergebnisse wertfrei übermitteln. An diesem Punkt können wir nur feststellen, wie viele Songs von einem bestimmtem Künstler oder einer bestimmten Künstlerin von Spotify als unpopulär eingestuft wurden und welche Songs und Künstler:innen es in die Top 200 geschafft haben. Über die musikalische Qualität der Songs lässt sich keine Aussage machen.
Data Mining Vorgehen & Methoden
Trotzdem liefert uns die Betrachtung der beiden Balkendiagramme bereits erste interessante Beobachtungen. Denn Künstler, die als unpopulär eingestuft werden, scheinen insgesamt mehr Tracks gelistet zu haben als Künstler mit Songs in den Charts. Im nächsten Schritt ist es dann wichtig, Gründe für das Verhalten der Daten zu finden. Denn nur so lassen sich die Beobachtungen zu echtem Wissen transformieren. Die Frage ist in diesem Fall also: Produzieren die unpopulären Künstler tatsächlich mehr Songs?
In diesem Fall ist ein Grund für diese Beobachtung schnell gefunden. Es ist so, dass unsere Datengrundlage eine Lücke enthält. Die unpopulären Songs haben alle einen Popularitätswert von maximal 18. Der Popularitätswert aus den Chart Songs fehlt, aber es kann davon ausgegangen werden, dass dieser eher hoch ist, bei etwa 90 – 100. Damit fehlen alle Songs mit einer Popularität von 19 – 89. Es könnte also sein, dass bspw. The Weeknd mit 32 Songs in den Charts war, jedoch mit vielen weiteren produzierten Songs etwas weniger erfolgreich war. Allerdings noch über dem Popularitätswert von 18. Somit tauchen diese Songs nicht in der Übersicht auf. Eine Antwort darauf, welche Künstler:innen insgesamt am meisten produzieren, lässt sich also nur mit einem Datensatz über alle in Spotify gelisteten Songs treffen. Diese wichtige Erkenntnis über den Datensatz muss bei zukünftigen Analysen berücksichtigt werden.
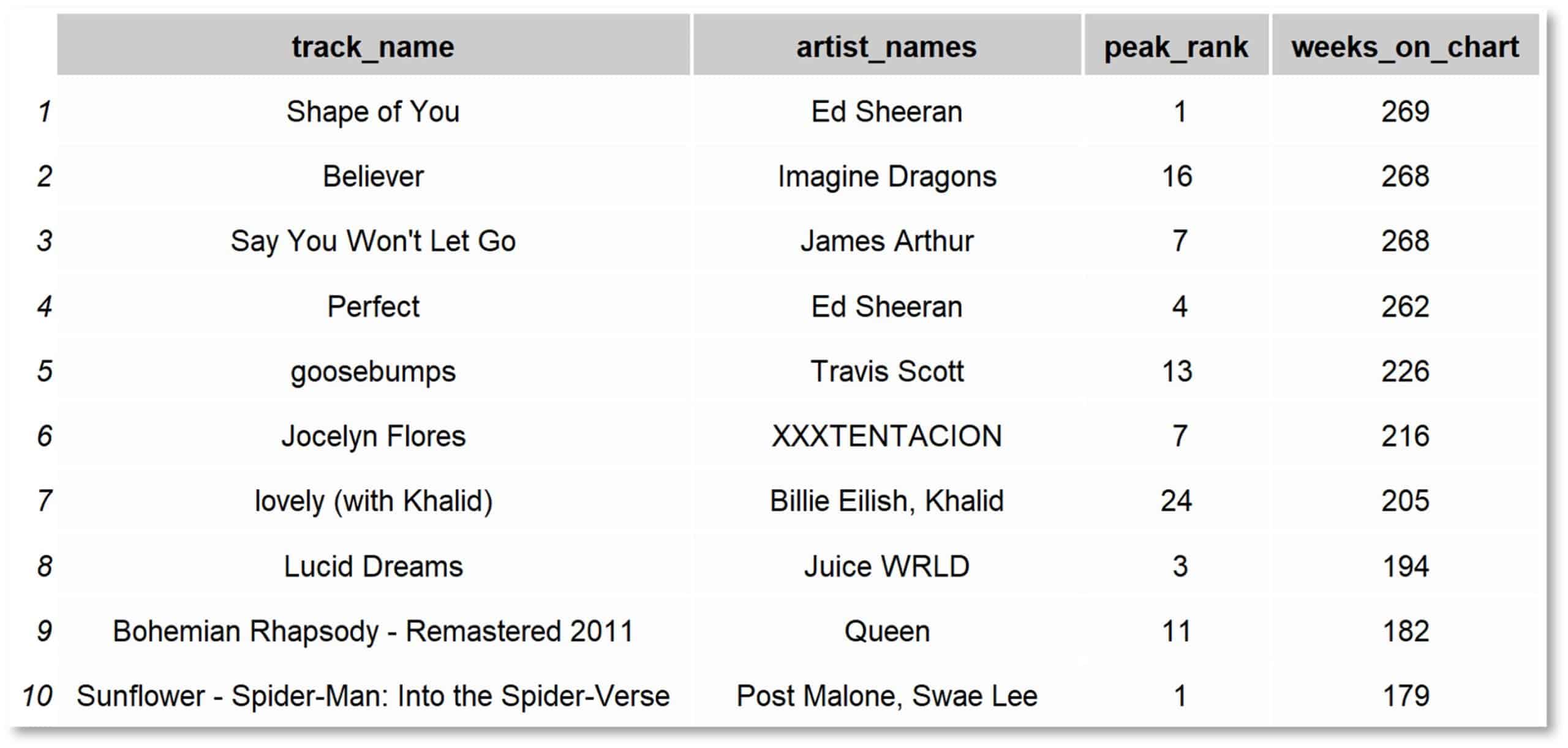
Betrachtet man die Top Tracks sortiert nach der Gesamtzahl an Wochen in den Charts, so wird man als regelmäßige:r Radio Hörer:in in seinen Annahmen wahrscheinlich bestätigt. Die meisten Songs sind sehr bekannt und es ist nicht verwunderlich sie in dieser Tabelle wiederzufinden. Trotzdem liefert auch diese Tabelle wichtige Erkenntnisse für den Data Miner. Denn auch vermeintlich triviale Dinge müssen zunächst in den Daten bestätigt werden, um die Zuverlässigkeit des Datensatzes zu gewährleisten. Denn wie soll ein Vertrauen in komplexe und aufwendige Analyse aufgebaut werden, wenn der Datensatz weitestgehend unbekannt ist und nicht auf seine Plausibilität überprüft wurde?
Bringt man den Peak Rank, den höchsten erreichten Platz in den Charts, eines Songs mit der Gesamtdauer in den Charts in Verbindung, so fällt auf, dass eine hohe Platzierung und eine lange Dauer miteinander in Verbindung stehen. Auch dieses Verhalten kann genauer untersucht werden. Dazu kann man die Verteilung der beiden Werte in einem sogenannten Histogramm betrachten. Hierbei ist der entsprechende Wert auf der x-Achse und dessen Häufigkeit auf der y-Achse dargestellt.
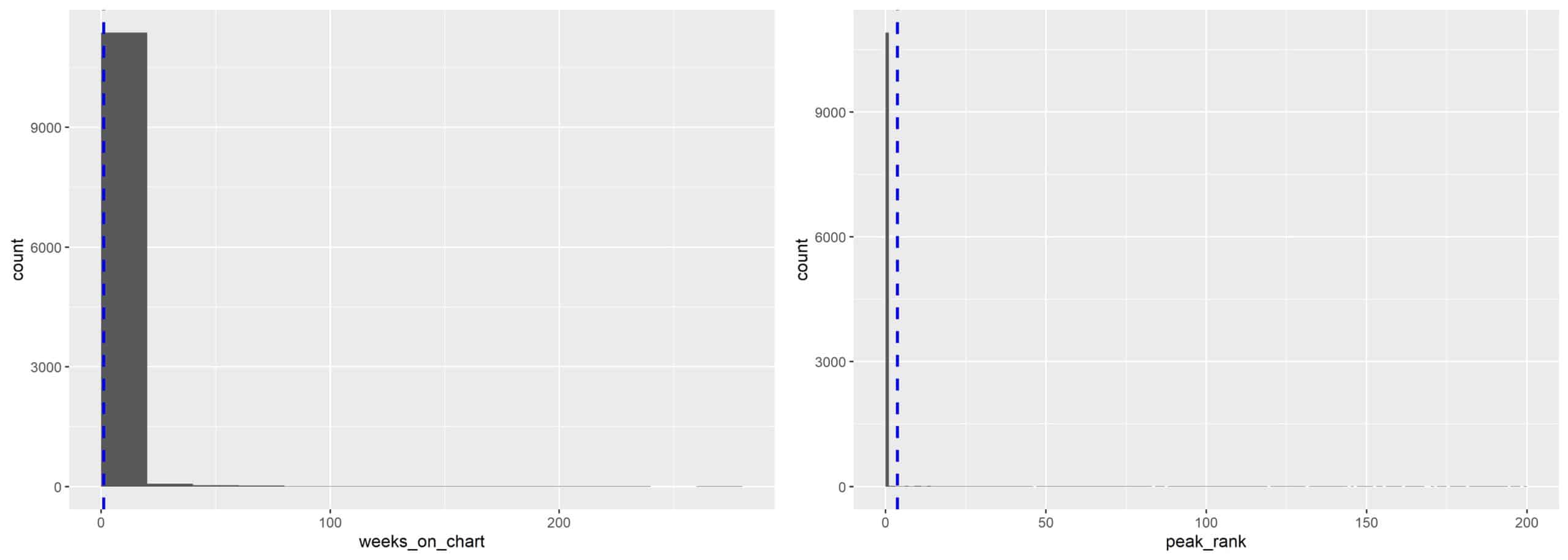
Dabei fällt sofort auf, dass die meisten Songs sowohl eine sehr hohe Chart-Platzierung als auch nur eine kurze Zeit in den Charts vorweisen. Beide Histogramme sind sehr stark zur Null verschoben. Auch bei diesem Diagramm sollten sich triviale Vermutungen bestätigen lassen. Dieses extreme Verhalten ist eher gegensätzlich zur intuitiven Vermutung der Verteilung.
Der Grund für dieses Verhalten liegt in diesem Fall nicht in den Daten selbst, sondern in einer vom Data Miner durchgeführten Transformation der Daten. Um fehlende Werte der unpopulären Songs in den Spalten „Peak Rank“ und „Week on Charts“ auszugleichen, wurden diese Felder mit einer Null befüllt. Kontextuell ist diese Herangehensweise sicherlich richtig und sinnvoll, da diese Songs ja tatsächlich null Wochen in den Charts waren und die Platzierung nicht innerhalb der Range 1-200 liegt. Bei der Anwendung bestimmter Verfahren kann diese Transformation jedoch drastische Auswirkungen haben, wie in den beiden Diagrammen gesehen werden kann. Deshalb ist es beim Data Mining wichtig, jede durchgeführte Datentransformation zu hinterfragen und deren Auswirkungen in den Daten zu überprüfen. Somit vermeidet man, dass auch die komplexen Analysen verzerrte Ergebnisse liefern.

Filtert man die unpopulären Songs aus den Histogrammen komplett heraus, erhält man direkt ein nachvollziehbareres Ergebnis. Beide Diagramme zeigen nach wie vor eine eher linksschiefe Verteilung, d.h. viele Songs sind nur für eine kurze Zeit in den Charts. Auf der anderen Seite erreichen viele Songs auch eine hohe Platzierung in den Charts. Ein direkter Zusammenhang lässt sich mit dieser Visualisierung jedoch noch nicht ableiten.
Besser geeignet für eine solche Analyse ist ein sogenannter Scatter-Plot (je ein Wert auf der x-Achse und ein Wert auf der y-Achse).
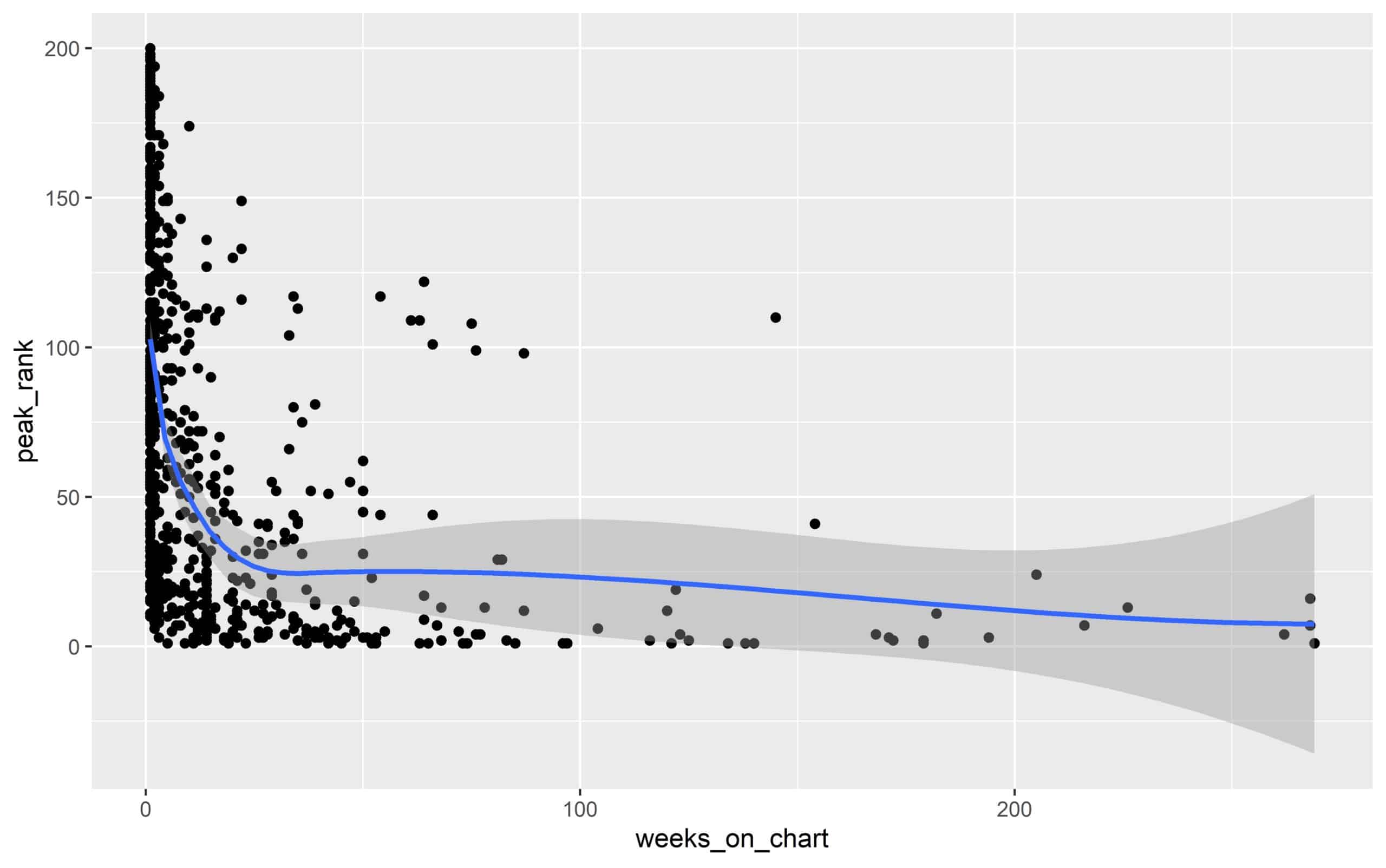
Hierbei sieht man, dass Songs, die lange in den Charts sind, tatsächlich auch sehr hoch platziert sind. Andersrum gibt es auch eine Menge Songs, welche nur kurz in den Charts und eher im unteren Bereich platziert sind. Führt man dieses Vorgehen fort, lassen sich mit ein bisschen musikalischem Kontext vier Punktewolken identifizieren:
- Sehr erfolgreiche Tracks (rot)
- „One-Hit-Wonder“ (lila)
- „Liebhaber“ Songs (gelb)
- „Gummibälle“, ploppen nur kurz und weit unten in den Charts auf (türkis)
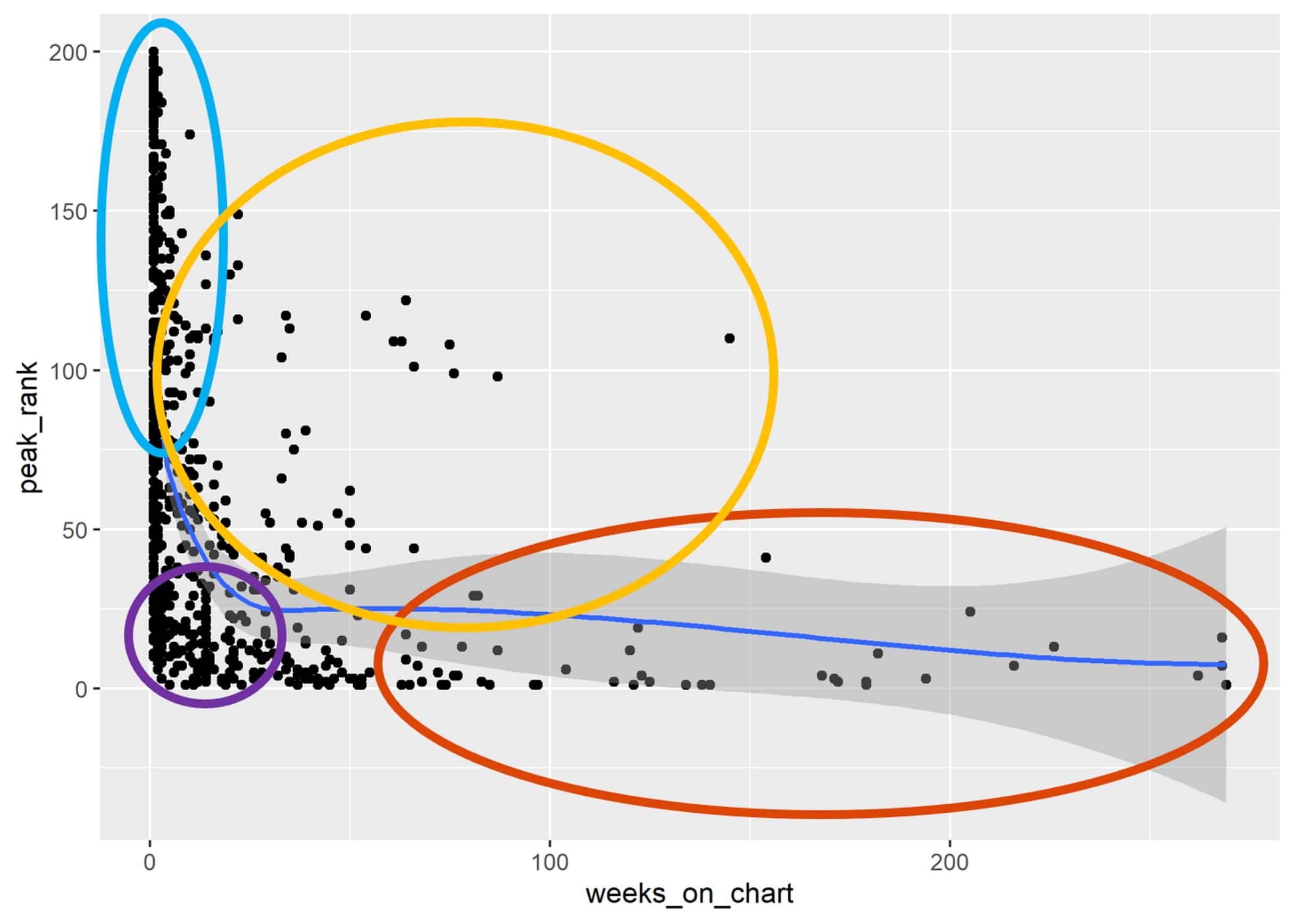
Die Einteilung der Gruppen erfolgte in diesem Fall händisch und ohne umfassendes musikalisches oder statistisches Fachwissen. Das Prinzip, das dahinter steckt wird jedoch beim Data Mining sehr häufig angewendet und nennt sich Clusteranalyse. Die Clusteranalyse hat zum Ziel, innerhalb eines Datensatzes Gruppen zu definieren. Innerhalb dieser Gruppe sind Datenpunkte ähnlich zueinander und auf der anderen Seite unähnlich zu Punkten außerhalb der Gruppe.
Bekannte Verfahren der Clusteranalyse sind:
- Hierarchical Clustering
- K-Means / K-Prototype
- DB Scan
- Spectral Clustering
- Support Vector Machines
👉🏼 Mehr Infos dazu könnt ihr in unseren vorangegangen Blogbeiträgen zur Clusteranalyse finden: Teil 1 & Teil 2.
Eine durch eine statistische Methode durchgeführte Clusteranalyse hat mehrere Vorteile gegenüber einer händisch durchgeführten. Zum Beispiel ist sichergestellt, dass ein statistisches Verfahren objektiv und weniger durch Vermutungen und Vorwissen beeinflusst ist. Somit ist es besser geeignet für weitere Diskussionen und Fragestellungen.
Außerdem ist ein statistisches Verfahren in der Lage, auch für hochdimensionale Fälle ein Ergebnis zu liefern. Ist ein Zeichnen von Sphären im zwei- oder dreidimensionalen noch möglich, so lassen sich Daten im vier- oder mehrdimensionalen gar nicht mehr visualisieren. Spätestens dann ist man auf eine Methode, welche diese Prozesse durchführen kann, angewiesen.
Wichtig ist jedoch, sich klarzumachen, dass statistische Methoden in den meisten Fällen die erweiterte Lösung von realen Fragestellungen sind. Die Einteilung von Datenpunkte in gewisse Gruppen ist ein wiederkehrender Prozess im Bereich des Data Minings, weshalb entsprechende Methoden extra dafür entwickelt wurden.
Wendet man nun ein clusteranalytisches Verfahren auf die obigen Daten an, bekommt man ein ganz ähnliches Ergebnis wie bereits vermutet. Das Verhalten innerhalb der Gruppen kann nun mit Hilfe von entsprechendem Fachwissen weiteruntersucht und aufgestellte Hypothesen bestätigt werden.
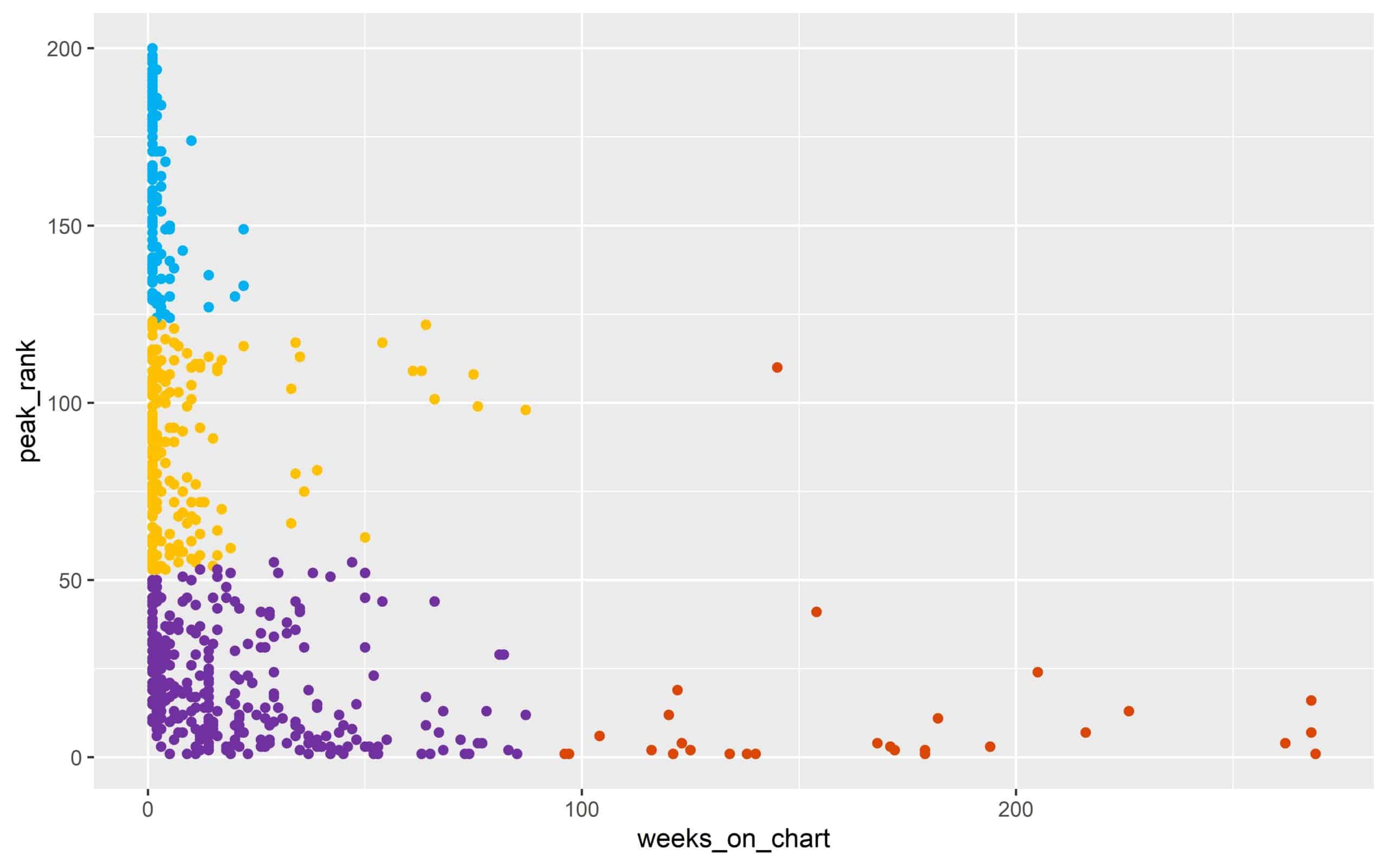
Neben dem Verhalten der Chart-Songs, kann auch ein Vergleich der populären und unpopulären Songs interessant sein. Aus diesem Grund kann man sich die Mittelwerte der verschiedenen beschreibenden Merkmale einmal genauer anschauen.
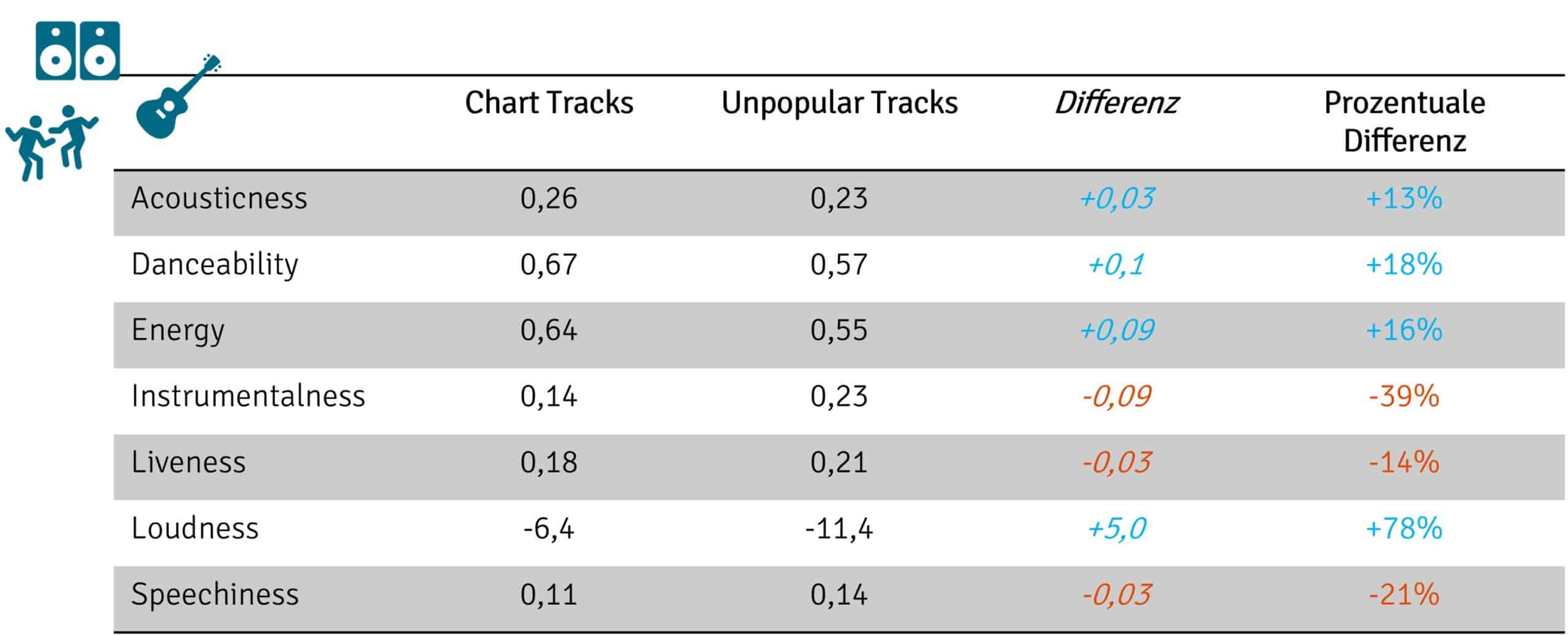
Mit Ausnahme der „Loudness haben alle Werte einen möglichen Bereich zwischen 0 und 1. Die Loudness dagegen nimmt Werte zwischen -60 und 0 an.
Betrachtet man die Mittelwerte der beiden Musikgruppen, so können in den allen Fällen nur minimale absolute Unterschiede beobachtet werden. Und auch die prozentuelle Veränderung der Mittelwerte bietet nur wenig mehr Erkenntnisse. Denn was soll schon bedeuten, dass eine Song 13% tanzbarer ist als ein anderer? Einen besseren Vergleich der beiden Gruppen liefert die Visualisierung über sogenannte Boxplots.
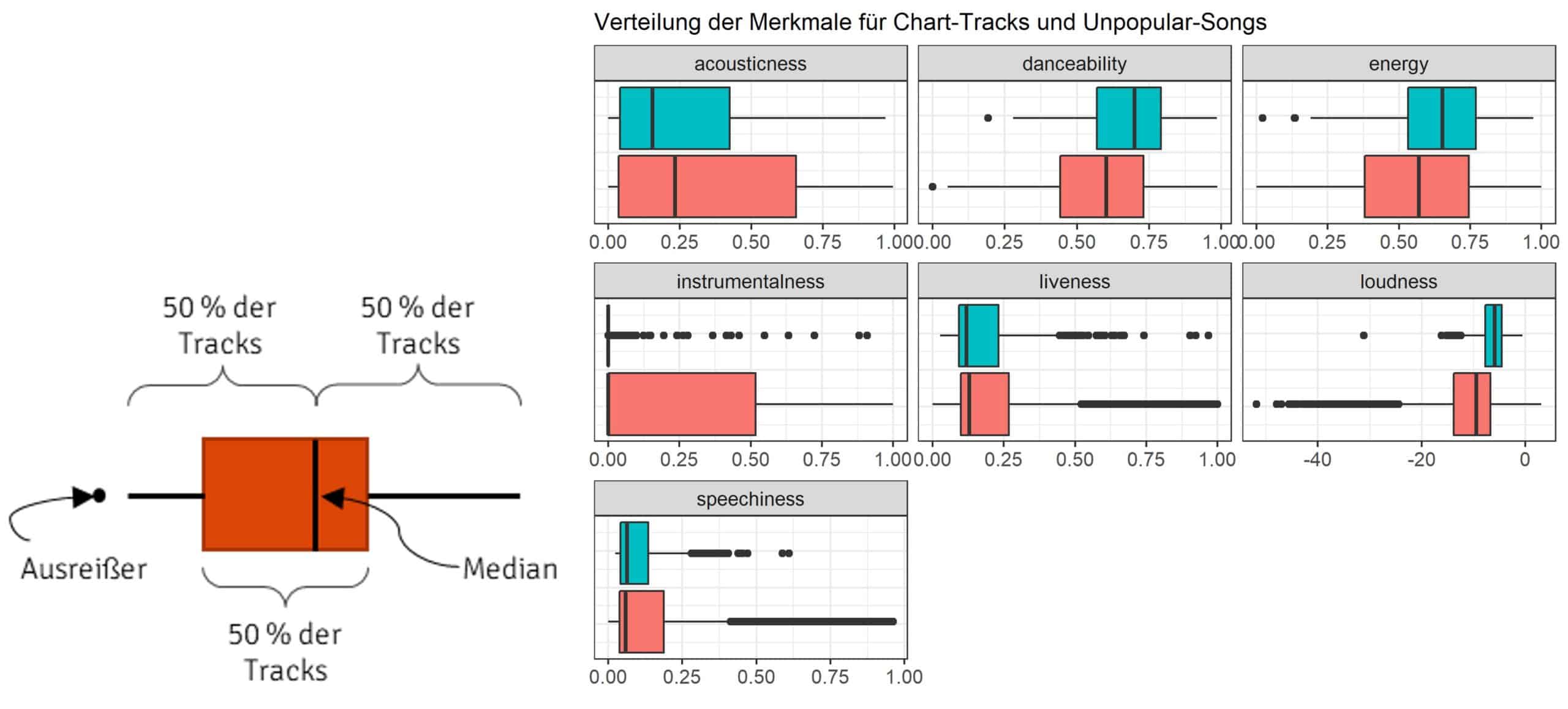
Ein Boxplot bietet auf einen Blick eine Übersicht über
- die Min und Max Werte,
- die Symmetrie der Verteilung,
- die Spannweite,
- und mögliche Ausreißer.
Damit haben sie sehr viel mehr Aussagekraft als beispielsweise Mittelwerte und sind zudem auch viel anschaulicher. Wir können so direkt ablesen, dass Chart Tracks tanzbarer und nur selten instrumental sind. Unpopuläre Tracks sind dagegen etwas leiser, akustischer und instrumentaler. Live-Songs sind in beiden Gruppen eher untervertreten.
Auffällig ist auch, dass Chart Tracks fast in allen Fällen nicht instrumental sind und einen Wert von Null vorweisen. Anhand des Mittelwerts lässt sich dieser Umstand nicht ablesen, was auf die starke Sensitivität auf Ausreißer zurückzuführen ist. Denn nur aufgrund der Ausreißer in den Daten kommt der Mittelwert von 0.14 zustande, was ein schiefes Bild der tatsächlichen Datenlage vermittelt.
An diesem Beispiel erkennt man, dass man sich stets über die Schwächen und Stärken der jeweiligen statistischen Verfahren im Klaren sein muss. Um diese zu relativieren, ist es ebenfalls wichtig, die Daten stets aus mehreren Blickwinkeln (z.B. geeignete Visualisierungen) zu betrachten, um versteckte Strukturen sichtbar zu machen.
Daten-Anomalien rechtzeitig erkennen
Ein wichtiger Faktor, welcher oft zu verzerrten Analysen führen kann, ist die Existenz der oben genannten Ausreißer. Deren Identifikation nimmt auch ein großes Anwendungsgebiet innerhalb des Data Minings ein. Allgemein versteht man unter einem Ausreißer oder einer Anomalie die Abweichung von einem erwarteten Zustand oder Wert. Der erwartete Wert ist durch eine Regel definiert. Ist die Regel bekannt, können die nächsten Werte berechnet werden. Entspricht der gemessene Wert nicht dem anhand der Regel berechneten Wert, handelt es sich um eine Daten-Anomalie.
Bei der Ausreißer Erkennung ist es dabei wahrscheinlich noch wichtiger, dass eigene Erfahrungen und Vermutungen nicht in die Analyse einfließen dürfen. Denn auch der Data Analyst ist häufig beeinflusst von Emotionen oder Annahmen und kann bestimmte Wahrscheinlichkeiten eventuell nicht richtig einschätzen. Umso mehr ist man auf die objektive Bewertung durch eine statistischen Methode angewiesen. Somit werden auch nur tatsächliche Anomalien als solche erkannt. Je mehr relevante Informationen dabei zur Verfügung stehen, umso besser lassen sich Anomalien in der Regel erkennen.
Wir konnten nun mit der gewählten Visualisierung die groben Unterschiede zwischen populären und unpopulären Songs ermitteln. Interessant wäre nun natürlich zu wissen, ob es ein „Geheimrezept“ gibt, um erfolgreiche Musik zu produzieren. Falls nicht, müsste es doch anhand der vorhandenen Daten zumindest möglich sein, die Wahrscheinlichkeit auf einen Chart-Hit zu erhöhen. Mit diesem Wissen könnte man direkte Handlungsempfehlungen ableiten, die einen Vorteil gegenüber der Konkurrenz verschaffen.
Aus der Betrachtung der Boxplots wissen wir bereits, dass eine positive Korrelation zwischen „Tanzbarkeit“, Energie der Songs und dem Erscheinen in den Charts besteht. Ebenso besteht eine negative Korrelation zu der akustischen und instrumentalen Ausprägung. An diesem Punkt ist es wieder wichtig anzumerken, dass die Korrelation nur beobachtet werden kann. Eine Kausalität, wie z.B. die Songs sind wegen ihrer „Tanzbarkeit“ oder Energie in den Charts, kann anhand der Daten nicht abgeleitet werden. Diese müsste erst mit ausreichend Domänenwissen verifiziert werden.
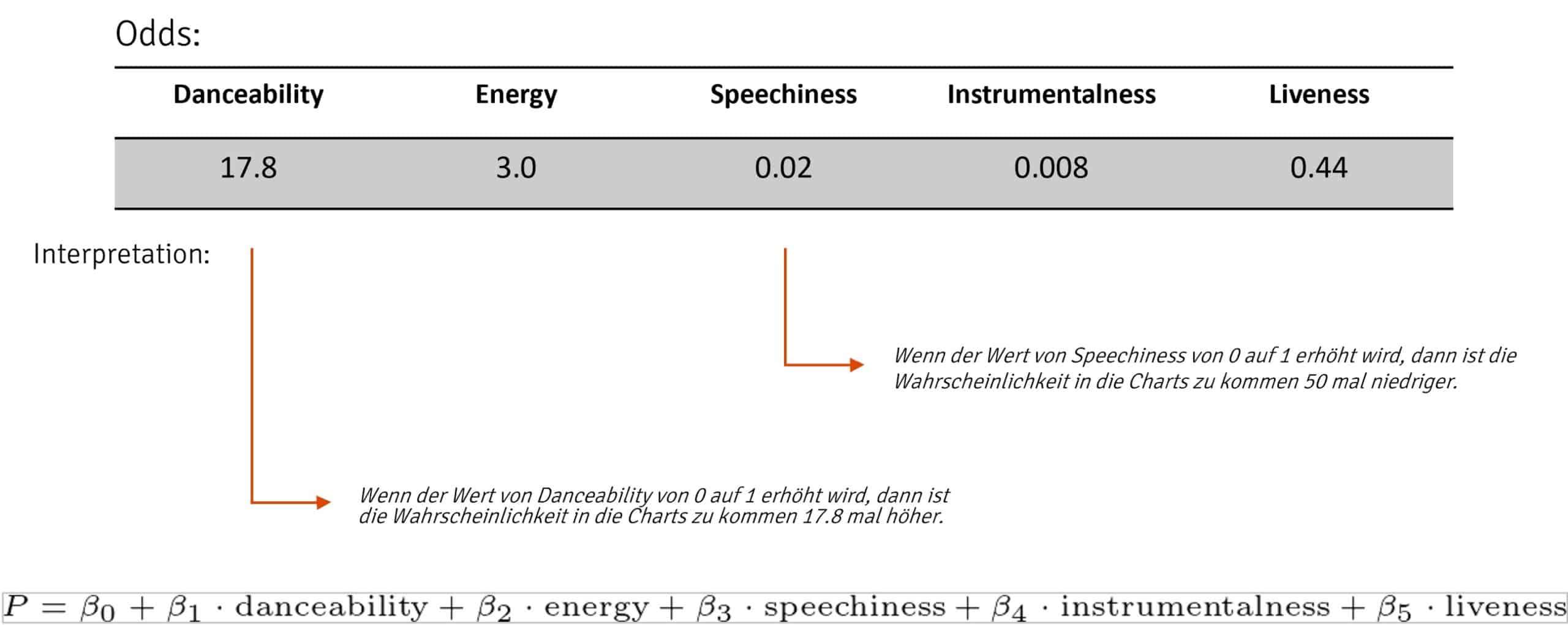
Versucht man die Korrelationen trotzdem zu nutzen, um eine Vorhersage über eine wahrscheinliche Chart-Platzierung zu machen, bspw. mit Hilfe einer logistischen Regression, so erhält man folgendes Modell.
Fazit: Sind Daten tatsächlich das „neue Öl“?
Wir sehen also, dass höhere Ausprägungen für die Werte „Tanzbarkeit“ und Energie, tatsächlich für eine sehr viel höhere Wahrscheinlichkeit sorgen, eine Chart Platzierung zu erhalten. Und diese Erkenntnis konnte man ganz leicht und ohne großen Aufwand mit frei verfügbaren Daten ermitteln. Mit Sicherheit nutzen große Produktionsfirmen diese Information, um eine große Menge an Songs zu produzieren, die genau diese Kriterien erfüllen. Somit erhoffen sie sich, einen Vorteil gegenüber der Konkurrenz zu verschaffen.
Glücklicherweise kann dies ganz leicht anhand der zur Verfügung stehenden Daten überprüft werden. Wenden wir dieses Modell beispielsweise auf Ed Sheerans Song „Shape of you“ an. Wie wir gesehen haben, war er sehr lange erfolgreich in den Charts platziert. Allerdings erhalten wir nur eine Wahrscheinlichkeit von 16% für eine Chart-Platzierung laut dem Modell. Zufall? Wohl eher nicht, denn tatsächlich wird für keinen einzigen Song, ob populär oder unpopulär, eine Wahrscheinlichkeit von über 50% berechnet. Das Modell taugt in der Realität also eher wenig.
Was lernt man nun daraus? Zum einen: Data Mining passiert nicht einfach, indem ein Modell auf Daten geschmissen wird. Es ist vielmehr ein sich wiederholender Prozess aus Hypothesen aufstellen, geeignete Werkzeuge finden und Ergebnissen evaluieren. Wichtig ist dabei jedoch, dass man auch akzeptieren muss, wenn das vermutete Ergebnis auch nach mehreren Versuchen nicht verifiziert werden kann. Denn in großen Datenmengen in es typischerweise so, dass wenn man lange und intensiv genug sucht, irgendwann auch den geringsten Zusammenhang finden wird. Auch wenn dieser in der Anwendung keinen realen Einfluss haben wird oder – schlimmer noch – zu falschen Interpretationen führt.
Zum Anderen: Nur weil man Daten hat, hat man nicht automatisch einen Vorteil gegenüber Anderen. In unserem Fall ist es so, dass Musik und Trends sich nur schwer vorhersagen lassen. Man wird auch nicht automatisch erfolgreich, wenn man andere erfolgreiche Songs imitiert. Der Hörer bzw. die Hörerin entscheidet am Ende immer noch selbst, ob die Musik den eigenen Geschmack trifft oder nicht. Ganz gleich wie gut der Algorithmus dahinter ist. So ist es auch in anderen Fällen. Big Data & Co. steuert die Leute nicht fern und nicht jeder, der Daten besitzt, hat auch automatisch bessere Chancen. Daher ist der Slogan: „Daten sind das neue Öl“ in vielen Fällen oft einfach ein Marketing Slogan.
Du hast Fragen zu unserem Blogpost oder findest das Thema Data Mining spannend? Dann melde Dich gerne direkt bei uns.